

Språkteknologisk upptäcktsfärd med KB-BERT
Hos KB-labb utvecklas språkmodeller som på sikt kommer att underlätta sökning och navigering i KB:s digitaliserade samlingar. Ibland med lite hjälp från mänskliga KB-medarbetare.
 Förstora bilden
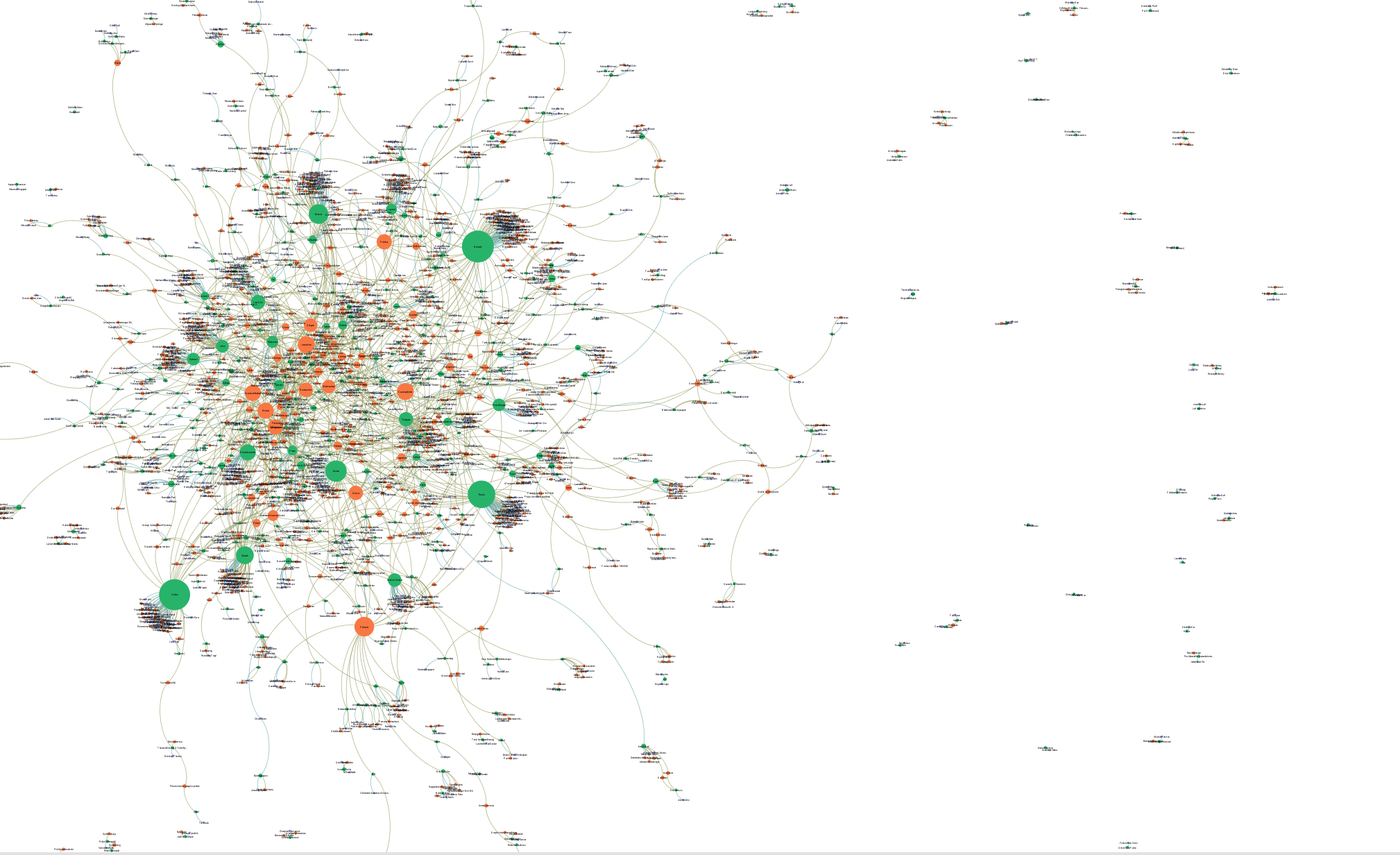
Förstora bildenVisualisering av metadata över förlag och ämne från utgivningen av biografier i Sverige 2014.
Metadata – data om data
I bibliotekskataloger är vi vana vid att söka på titlar, författare, ISBN, förlag och ämnesord för att få fram data om den källa vi söker. Kanske vill vi hitta alla böcker av vår favoritförfattare, se vilka titlar som finns som ljudbok eller bevaka utgivningen inom ett visst forskningsfält. De här uppgifterna i bibliotekskatalogen kallas metadata, enkelt uttryckt data om data.
Med digitaliseringen har våra förväntningar förändrats. Idag ses det som en självklarhet att kunna söka direkt i innehållet i en digitaliserad källa. Kvalitativ metadata är en förutsättning för önskade sökresultat i KB:s digitaliserade samlingar. På KB-labb undersöker vi hur användares behov kan mötas genom utveckling av metadata i en digital textsamling.
På bilden här ovan ser du en visualisering av utgivningsdata om ämne och förlag som KB:s katalogisatörer analyserar och registrerar. Med språkmodeller som utvecklas på KB-labb är målet att dessa och liknande uppgifter i framtiden till stor del kommer att kunna analyseras maskinellt.
Språkmodellen KB-BERT
Inom språkteknologi (automatisk bearbetning av text eller tal) finns det ett stort värde i att kunna identifiera så kallade namngivna entiteter (på engelska Named Entity Recognition, NER). Entiteter kan vara vad som helst, till exempel personnamn, platser, eller till och med tidsangivelser.
När man har identifierat alla namngivna entiteter i en text kan man använda dem till många olika syften. Ett namn behöver inte alltid betyda samma entitet. Vi har till exempel Hammarby (stadsdelen i Stockholm) som är en plats och Hammarby (fotboll) som är en organisation. Det här är ett exempel på hur annoteringen skapar förutsättningar för maskiner att känna av när samma ord kan ha olika betydelser beroende på sammanhang i en mening.
För att kunna identifiera entiteter automatiskt använder man så kallade språkmodeller. Man kan föreställa sig en sådan modell som en grundläggande språkförståelse skapad för att lösa olika uppgifter. För att åstadkomma detta tränas modellen att förstå språkets uppbyggnad. KB-labb publicerade våren 2020 en kraftfull språkmodell med namn KB-BERT som också tränades till att känna igen entiteter.
Här upptäcktes tidigt att det fanns problem med datamängden som hade använts till träningen. Den KB-BERT-baserade NER-modellen tränades på en datamängd som var delvis maskinannoterad och det fanns tydliga kvalitetsproblem med annoteringen. Det behövdes en NER-datamängd på svenska som höll en högre kvalitetsnivå, och KB-labb har nu avslutat ett projekt med att försöka ta fram en sådan med hjälp av mänskliga annoterare.
Annoteringsverktyget
KB-labb skapade och designade ett annoteringsverktyg och började jobba med att definiera användbara entitetskategorier. Vanligtvis brukar man få samma mening annoterad av flera olika personer för att sedan kolla hur väl deras bedömningar stämmer överens.
I det här projektet satsades i stället på en ständig dialog med volontärer. Sammanlagt deltog 24 frivilliga KB-medarbetare med erfarenhet av metadata och katalogisering i projektet. Genom KB-medarbetarnas insats kunde maskininlärningen förenas med metadataexpertisen på KB.
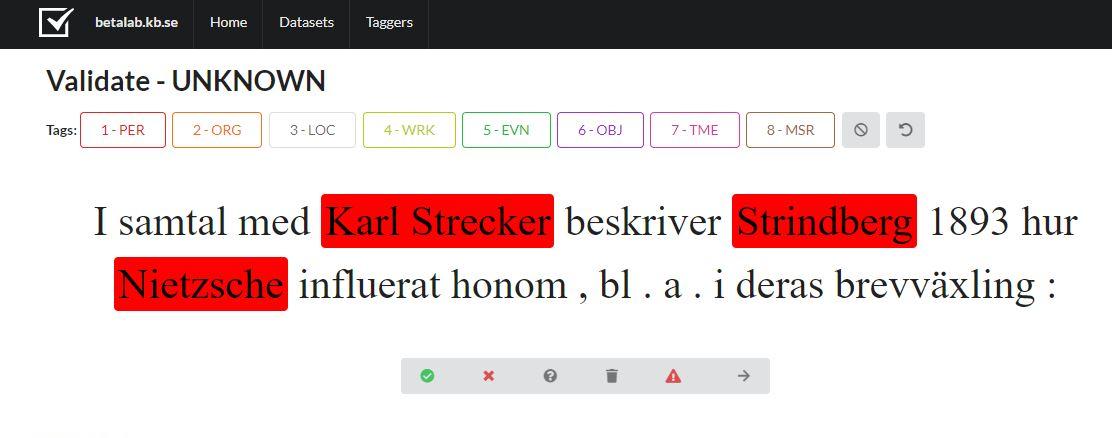
Så här kunde det se ut inne i annoteringsverktyget. De markerade termerna godkändes eller avslogs allt eftersom de dök upp.
Vi ville förbättra våra nuvarande och framtida modellers prestation genom att annotera en ny datamängd. Vi tog därför fram en datamängd som bygger på artiklar ur Wikipedia och som handlar om konstverk, böcker, filmer, konstnärer och artister. Skälet att välja dessa texter var att de innehåller mer av de entitetstyper som behövs i bibliotekssammanhang.
När projektet avslutades hade en datamängd på runt 23 000 annoterade meningar från svenska Wikipedia samlats in. Syftet med modellen är att den ska kunna användas för att skapa metadata automatiskt och kunna länka entiteter till varandra i en så kallad kunskapsbas. Denna och liknande modeller kan ha en stor inverkan på hur vi söker på och tillgängliggör KB:s digitala samlingar i framtiden.
Kategorier och entiteter
Här är några exempel på entiteter som var särskilt knepiga att kategorisera. I vilken kategori tycker du de passar bäst? Kategorierna är: person, plats, organisation, konstverk, evenemang, föremål, tid och mått. Meningarna är påhittade för att ge ett sammanhang till entiteten.
- Hon fick Augustpriset förra året.
- Kristendomen kom till Sverige på 800-talet.
- Den här vasen har daterats till Mingdynastin.
- Låten går att ladda ner på iTunes.
- Flickan var född i Krokeks församling.
I dagsläget är träningen av nya, mer kraftfulla modeller på KB-labb i full gång. Målet är att de här modellerna ska kunna annotera i princip varenda digitaliserad text som finns i KB:s arkiv med entiteter, och på så sätt göra samlingarna mycket lättare att söka på och navigera i. Till exempel skulle man kunna formulera frågan ”Kan jag få alla tidningssidor i DN år 2020 där ett konstverk nämns?”, och genast få fram svaret.
Med projektet som vi nu avslutat har vi tagit ett stort kliv närmare utökade möjligheter att forska och gå på upptäcktsfärd i KB:s samlingar.